DeepSeek and Peking University Open Source DSpark, an AI Inference Accelerator That Boosts Throughput by Up to 85%
There’s a quiet tension inside every AI chatbot: the model generates text one token at a time, each step requiring a full forward pass through billions of parameters. The longer the output, the longer the wait. DeepSeek, working with researchers at Peking University, just open-sourced a framework called DSpark that tackles this bottleneck head-on, and the numbers are striking.
DSpark is a speculative decoding framework — a technique that uses a lightweight draft model to quickly generate candidate tokens, then has the full-scale model verify them in a single batch. The verification step runs in parallel, and the rejection sampling mechanism guarantees the output distribution matches the original model. Speed goes up, quality stays the same.
The framework is already deployed in the preview engine for DeepSeek-V4-Flash and DeepSeek-V4-Pro. Compared to the previous production baseline — a single-token speculative decoding method called MTP-1 — DSpark delivers a 60–85% improvement in per-user generation speed at equivalent throughput levels. The paper and training code — plus model checkpoints — are all on GitHub.
The problem with guessing ahead
Speculative decoding is not new, but its real-world value depends on two things: how good the draft model is at generating candidates, and how efficiently the target model can verify them. Existing approaches fall into two camps.
Autoregressive draft models (like Eagle3) generate candidate sequences one token at a time. They model dependencies well and have high acceptance rates, but latency grows linearly with candidate length. In practice, this forces deployments to use short candidate blocks and shallow networks.
Parallel draft models (like DFlash) produce all candidate tokens in a single forward pass. Latency barely scales with candidate length, which sounds ideal. But because each position can’t depend on tokens sampled earlier in the same block, the acceptance rate drops sharply toward the tail of long candidates. The target model ends up wasting compute verifying tokens that get rejected anyway.
In a production environment with many concurrent requests, fixed-length verification makes this worse — the target model burns batch capacity on high-rejection-risk tail tokens, dragging down aggregate throughput.
Two mechanisms, one framework
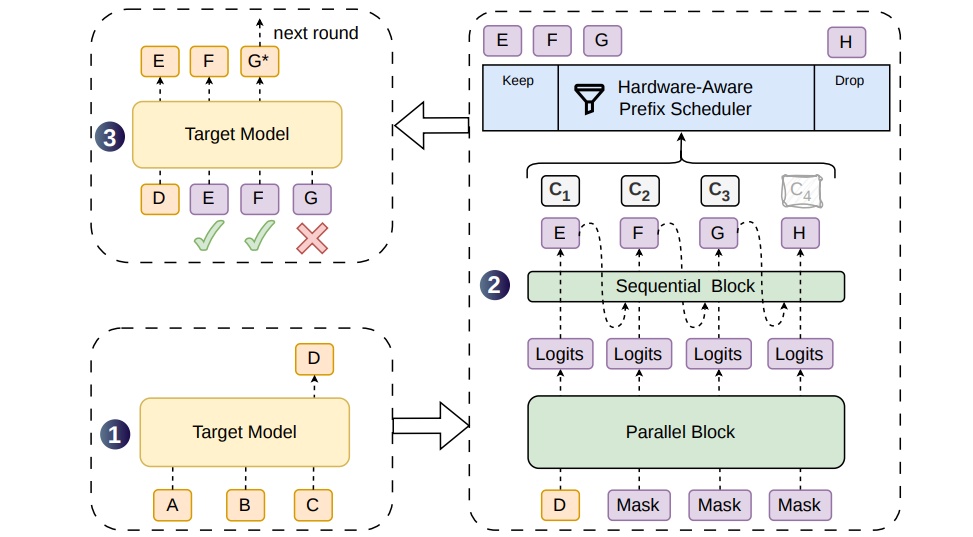
DSpark addresses both bottlenecks with a pair of complementary mechanisms.
First, a semi-autoregressive architecture that splits the work: a parallel backbone (based on an improved DFlash) produces hidden states and base logits for all candidate positions in one shot, then a lightweight sequential module injects prefix dependency information token by token. Two sequential module variants are offered — a Markov head that depends only on the previous token, and an RNN head that accumulates full prefix context through a recurrent state.
The benefit is clear in the benchmarks: a two-layer Transformer depth in DSpark matches or exceeds the acceptance length of a five-layer DFlash across every test domain. A small amount of autoregressive dependency beats simply stacking more parallel layers.
Second, a confidence-scheduled verification mechanism. The model outputs a confidence score at each candidate position, predicting the survival probability of that token given that all previous tokens have been accepted. These scores are calibrated against empirical acceptance rates on a validation set using per-position temperature scaling.
A hardware-aware prefix scheduler then treats the verification length decision as a global throughput maximization problem. Given a batch of concurrent requests and their per-position confidence scores, combined with empirically measured engine throughput curves, the scheduler dynamically decides how long each candidate prefix should be — prioritizing compute for the tokens with the highest global survival probability.
What the numbers say
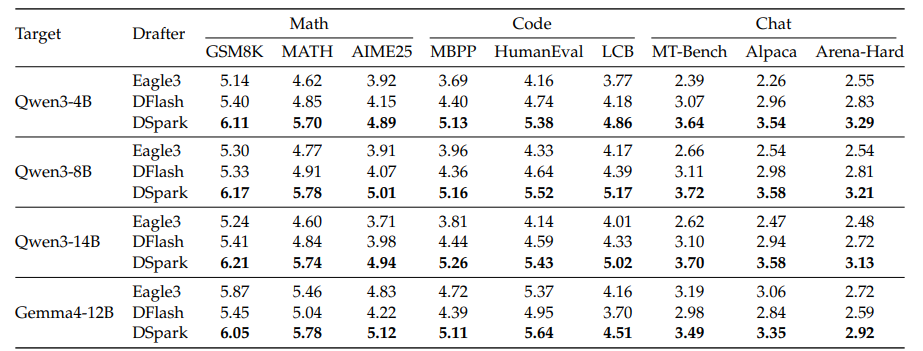
The research team tested DSpark against Eagle3 (autoregressive) and DFlash (parallel) using Qwen3 models (4B, 8B, 14B) and Gemma4-12B across three task categories: math reasoning (GSM8K, MATH500, AIME25), code generation (MBPP, HumanEval, LiveCodeBench), and general conversation (MT-Bench, Alpaca, Arena-Hard).
DSpark outperformed both baselines on average accepted length per round in every category. On Qwen3-4B, it beat Eagle3 by roughly 30.9% and DFlash by 16.3%.
A position-level conditional acceptance rate analysis reveals why: DFlash’s high first-position acceptance comes from the capacity advantage of deeper parallel networks, but acceptance drops sharply from position 2 onward. Eagle3 maintains stable or even rising acceptance at later positions but suffers at position 1 due to shallow networks. DSpark inherits the parallel backbone’s strong first-position capacity and tames the decay at later positions with sequential dependency.
In production: real traffic, real gains
In the preview deployment with DeepSeek-V4-Flash and DeepSeek-V4-Pro, DSpark’s draft model uses a parallel backbone with three MoE layers and sliding-window attention, a maximum candidate block length of 5, and a Markov head as the sequential module.
Two engineering optimizations went into training. First, only the target model’s hidden states are passed during parallel training (not the full vocabulary logits), cutting communication complexity from O(V) to O(d). Second, an anchor-length sequence packing strategy compresses randomly sampled prediction blocks into dense batches, avoiding the compute and memory overhead of traditional padding.
The production scheduler had to solve two real-world constraints. CUDA graph replay and zero-overhead scheduling require the next batch size to be determined before the current round finishes — synchronous scheduling would stall the GPU pipeline. The team made the scheduler asynchronous: candidate tokens are confidence-ranked using the current round, but the truncation length (batch capacity ceiling) is predicted from confidence data two rounds old, hiding the scheduling latency.
Variable-length verification prefixes also cause utilization issues in standard decoding kernels due to padding and load imbalance. The team decoupled physical execution from logical sequence tracking: all tokens are flattened into independent elements, and sequence-internal dependencies are carried through marker tensors in sparse attention. Only the index attention and compression kernels needed modification to support dynamic scheduling.
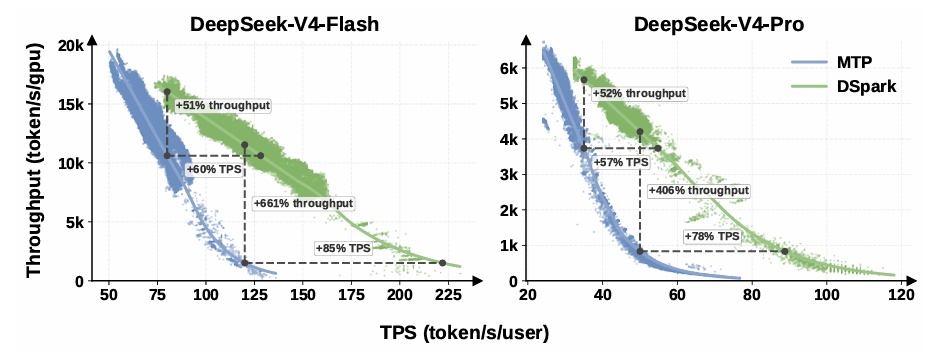
The live production results are concrete. On the V4-Flash engine, with an SLA guarantee of 80 tokens per second per user, DSpark delivered 51% higher aggregate throughput than the single-token MTP-1 baseline. When the SLA tightened to 120 tokens/sec — a level where the baseline was already hitting its operational ceiling — DSpark maintained viable concurrent batch processing with a 661% throughput advantage over the baseline.
On the V4-Pro engine, DSpark showed a 52% throughput improvement at a 35 token/sec SLA, and a 406% improvement at 50 token/sec. At matched throughput levels, per-user generation speed improved between 57% and 85%.
The scheduler also adapts to load. At low concurrency, it allocates 4–6 token verification lengths to make use of idle compute. As concurrency rises, it smoothly reduces verification length to avoid resource contention.
One caveat
DSpark’s parallel backbone still generates a full initial candidate block for every request, even when the suffix tokens are ultimately truncated by the scheduler. For complex queries with inherently low acceptance rates, that draft computation cost can’t be recovered.
Still, the framework — along with DFlash and Eagle3 — is now open source under the DeepSpec project on GitHub, with training code, evaluation scripts and model checkpoints available.
GitHub: https://github.com/deepseek-ai/DeepSpec
Hugging Face: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark