NVIDIA cuts DeepSeek V4 inference costs by 80% on Blackwell, boosts throughput 20x
Running a large language model in production is expensive. Every API call burns compute, and the bills pile up fast. NVIDIA just published the numbers on how much that equation has changed for one of the most popular models on the market.
The company announced Tuesday that its Blackwell platform, running DeepSeek V4 with a fully optimized inference stack, now delivers per-token costs as low as one-fifth of what they were a month ago. Token throughput per GPU has improved by as much as 20x.
NVIDIA has made per-token cost a headline metric for total cost of ownership in AI inference. For DeepSeek V4, it says Blackwell now offers the lowest in the industry.
The optimization work runs across three layers. The production operations layer handles distributed serving, orchestration, scaling, and memory management — the infrastructure that keeps a model alive under real traffic. The application acceleration layer focuses on runtime optimizations: overlapping computation with communication, fusing kernels to cut overhead, and shaving latency at the framework level. The infrastructure access layer manages how the system calls into GPU, networking, memory, and system capabilities.
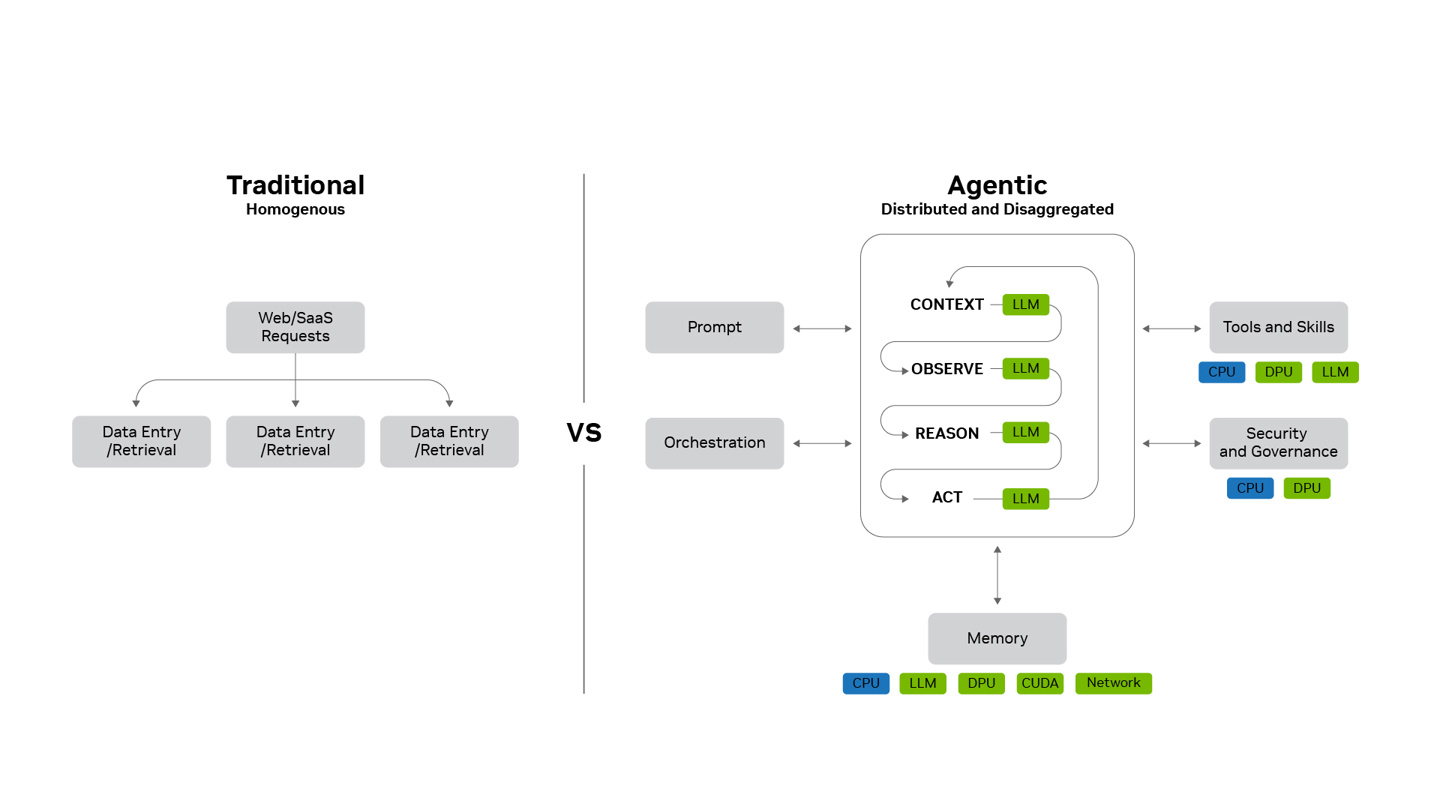
On the performance side, NVIDIA credits several specific techniques for the gains. Disaggregated serving decouples prefill and decode phases so resources are used more efficiently. Large-scale expert parallelism spreads Mixture-of-Experts workloads across GPUs. Parallel communication runs over NVLink. NVFP4 precision shrinks the bit width of compute without hurting output quality. And multi-token prediction lets the model generate multiple tokens per forward pass.
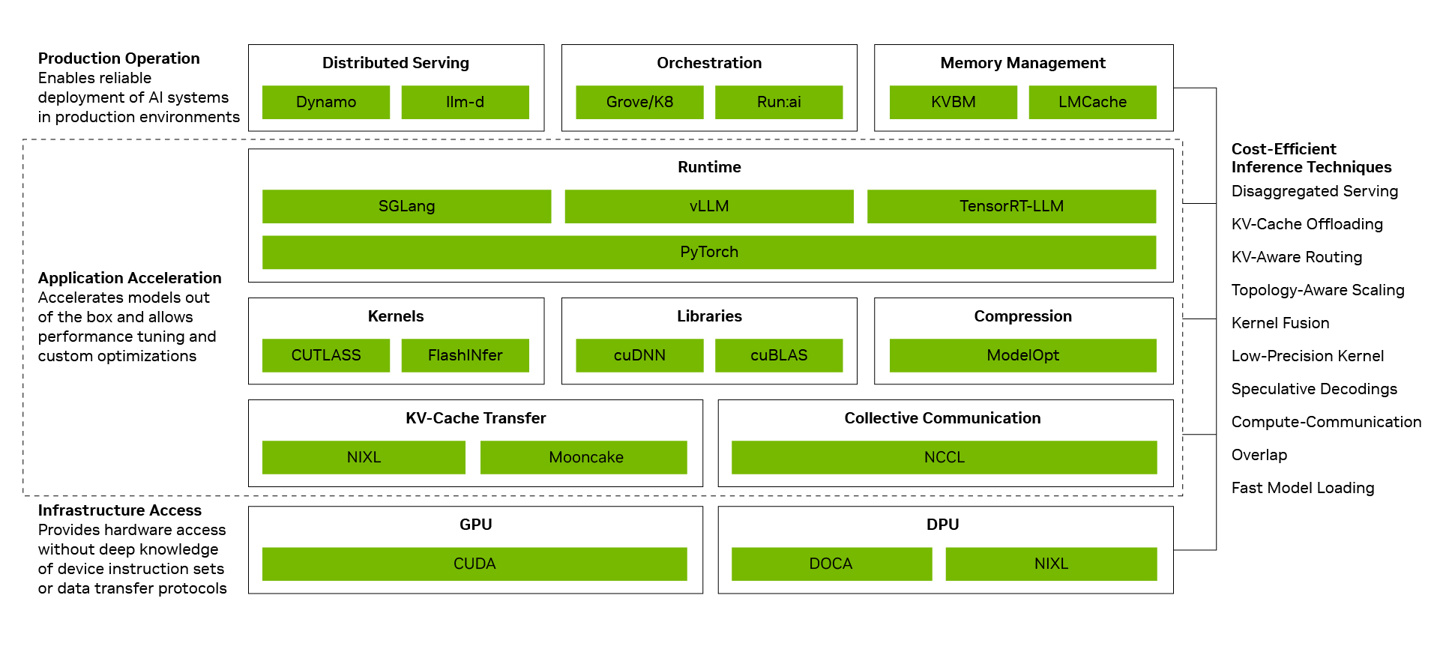
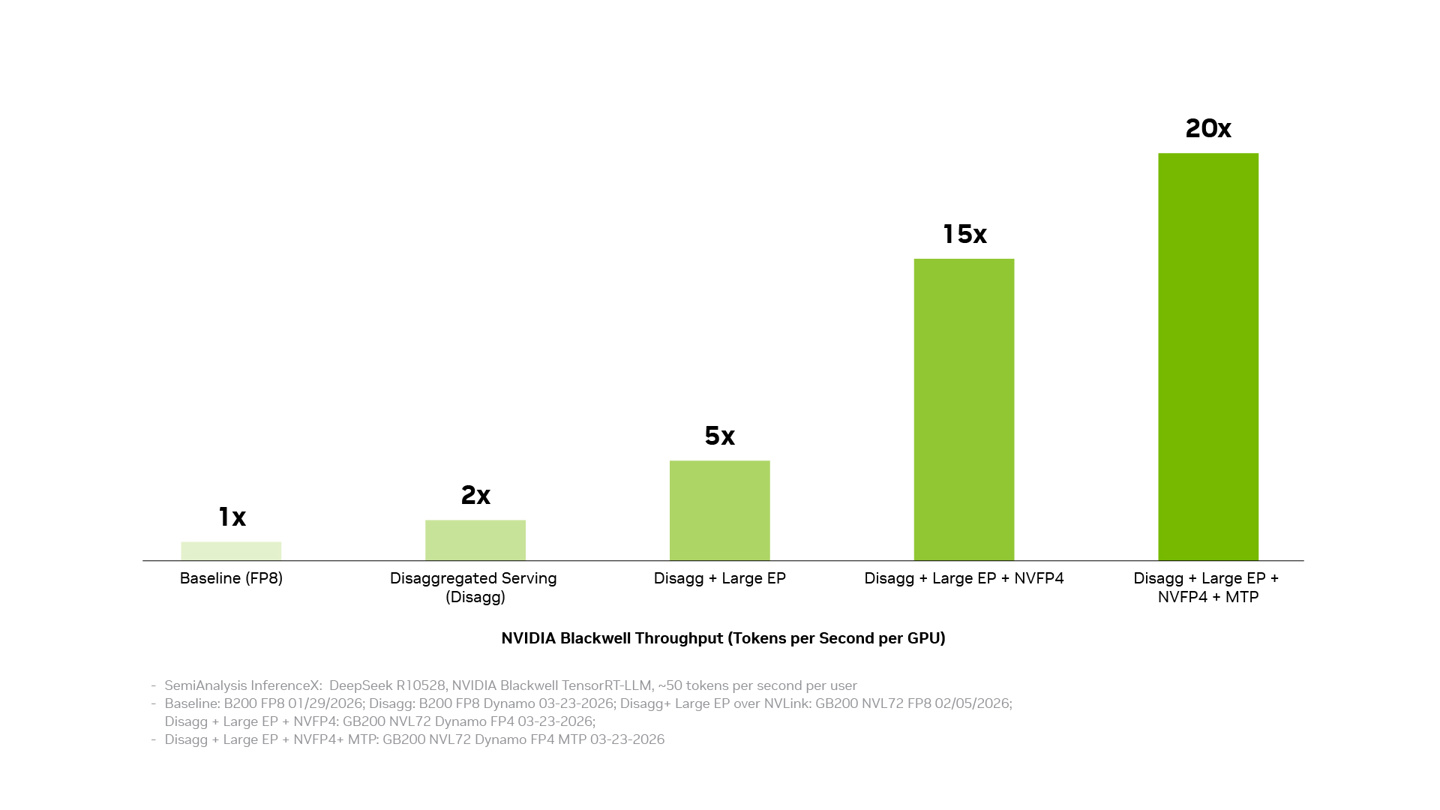
Taken together, these changes produce a 20x improvement in token throughput per GPU on Blackwell compared to the initial DeepSeek V4 deployment from a month ago. In dollar terms, running the same inference workload now costs roughly 80% less.
Developers running DeepSeek V4 at scale — for chatbots, coding assistants, or agent applications — are the direct beneficiaries. The improvements come from software alone, not new hardware, which means anyone already on Blackwell can get the gains through a stack update.