OpenAI's GeneBench-Pro doesn't let AI models cheat on biology — and most of them fail
OpenAI released a new benchmark Tuesday called GeneBench-Pro, and it is not the kind of test you can cram for. Instead of asking an AI model to recite facts or follow a fixed procedure, it drops the model into a messy, incomplete dataset and asks it to figure out what to do.
The idea is simple: real biology research is not a multiple-choice exam. A scientist staring at a genome sequence does not have a clean prompt and four options. They have noise, gaps, and conflicting signals. GeneBench-Pro tries to measure whether AI can handle that reality.
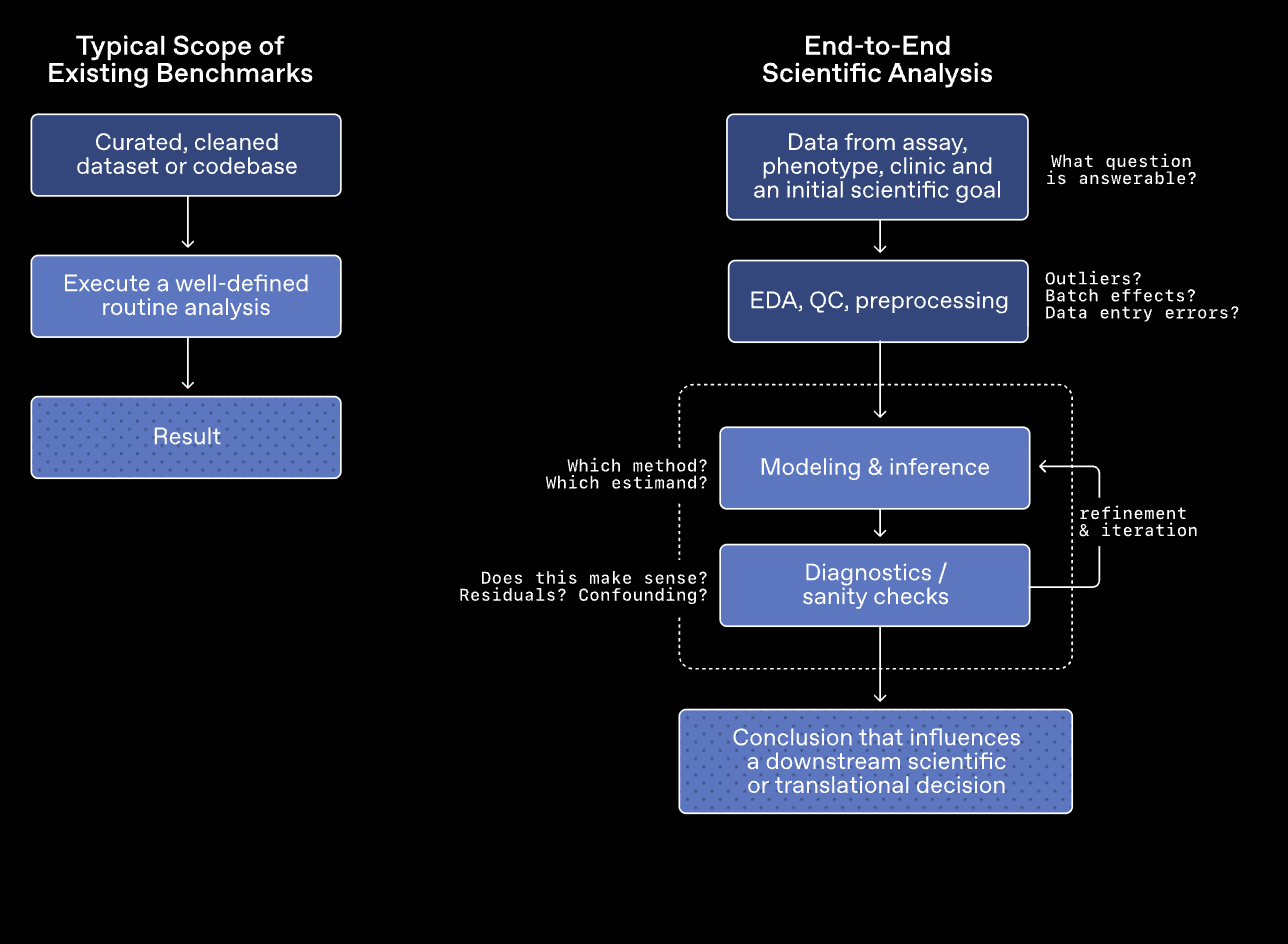
The benchmark covers 129 questions across 10 major domains and 21 subfields — statistical genetics, population genetics, functional genomics, proteomics, and quantitative biology among them. Each question hands the model a dataset that looks like something a researcher would actually work with, a short experimental context, and a decision-oriented question. The model has to explore the data, pick an analytical method, revise its approach when something does not work, and land on an answer.
Traditional benchmarks have a blind spot here. When you load up questions drawn from real historical data, there are often multiple valid paths to a correct answer. A model can stumble onto the right result using a flawed method and still score points. GeneBench-Pro sidesteps that by using synthetic data instead.
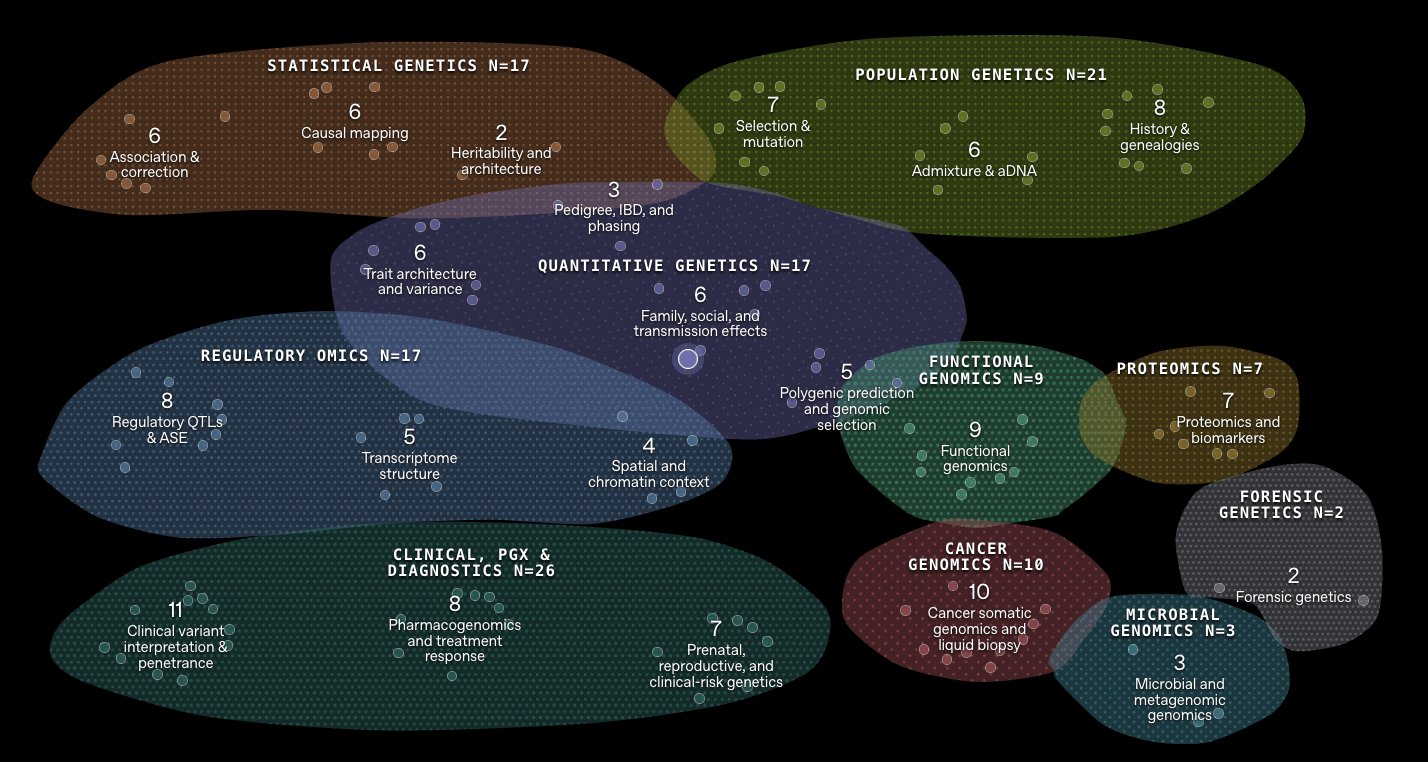
OpenAI controls the entire causal structure behind each synthetic dataset — it knows exactly which variables drive which outcomes — so it can tell whether the model actually understood the problem or got lucky. That is the difference between knowing biology and guessing biology.
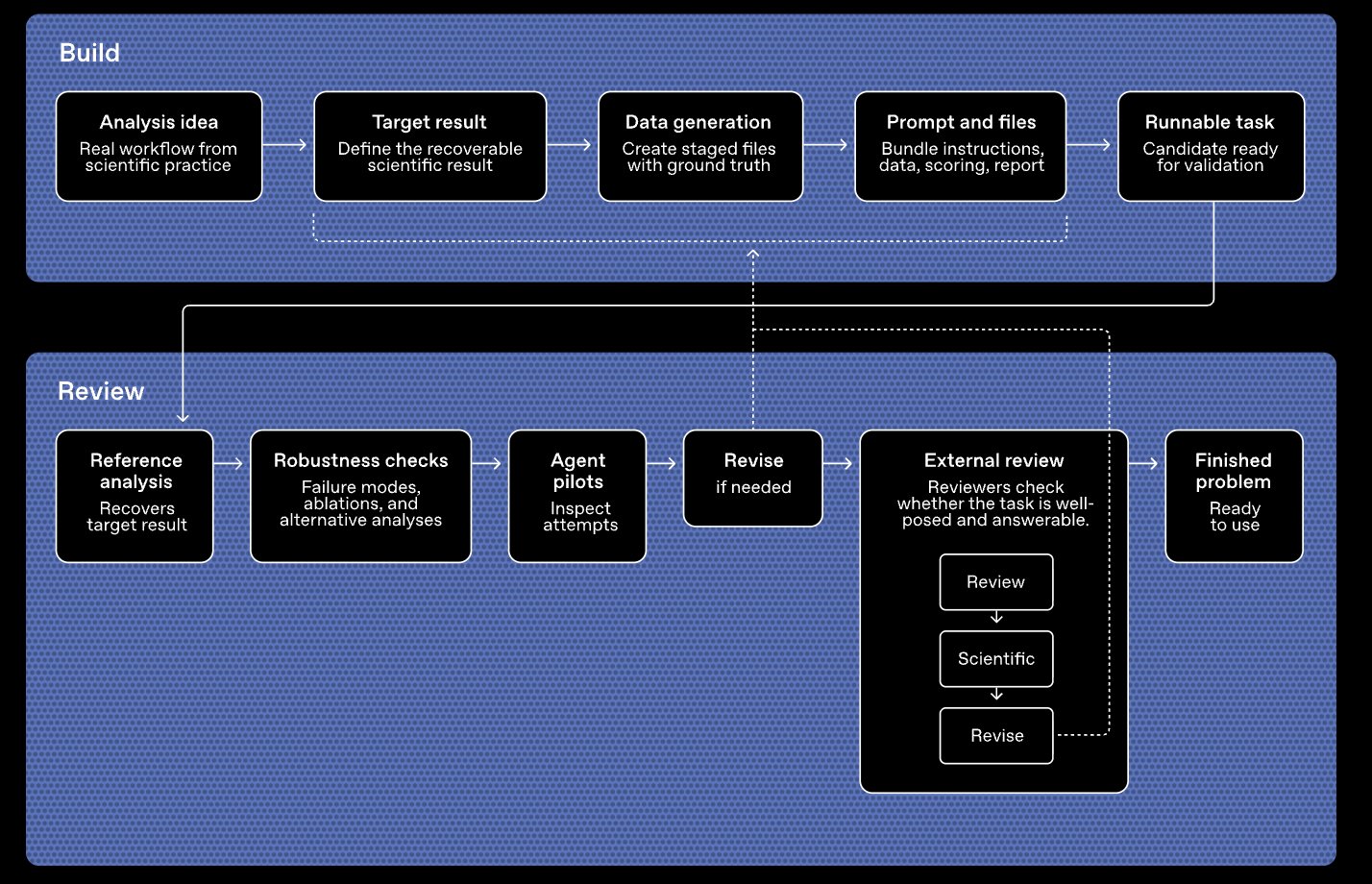
OpenAI has already open-sourced 10 representative questions on Hugging Face, along with an interactive interface for researchers to try. It plans to release 50 more to Artificial Analysis for independent third-party evaluation, which should give the field a clearer picture of how different models stack up when the training data crutch is taken away.
The early results are not public yet, but the structure of the benchmark suggests most general-purpose models will struggle. These are not coding problems or trivia questions — they require sustained reasoning over unfamiliar data. That is exactly the gap OpenAI is trying to measure.