Meta built a custom chip to put old DDR4 memory in new AI servers
When a server reaches the end of its three-to-five-year lifecycle, most of its components get scrapped or recycled. But Meta noticed something: the DDR4 memory modules inside those machines can keep working for seven to ten years. So the company built a custom chip to bridge that gap.
At the ISCA 2026 conference on Monday, Meta unveiled Vistara — a custom ASIC designed around the Compute Express Link (CXL) standard that lets new servers reuse DDR4 memory pulled from old ones. It’s already running in production across millions of servers inside Meta’s infrastructure.
The idea is straightforward. Servers wear out faster than memory does. With memory prices under pressure globally, pulling DDR4 DIMMs out of decommissioned machines and plugging them into new servers saves money that would otherwise go toward buying fresh DRAM.
The technical challenge is that modern servers run DDR5, not DDR4. You can’t just stick an old module into a new slot and expect it to work.
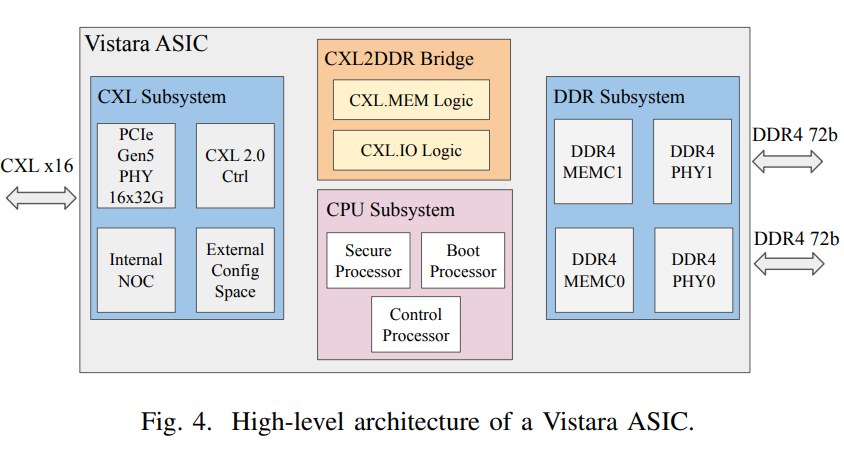
Meta’s Vistara ASIC solves this through a PCIe Gen5 x16 interface that complies with CXL 2.0 and 1.1 specifications. Each chip has two independent 72-bit DDR4 memory channels running at up to 3200 MT/s, supporting up to 256 GB per chip when using 64 GB DIMMs.
“We found that most CXL solutions bundle DRAM with the controller, which makes it impossible to reuse DIMMs,” Meta’s paper notes. “They also typically don’t support DDR4, which is a requirement for reusing old memory. High power draw and cost further limit their appeal.”
Meta deploys Vistara inside a system called MemServer. Each unit runs a single AMD Turin processor with 158 cores and 316 threads, paired with 768 GB of DDR5 memory. The Vistara ASIC adds another 256 GB of recycled DDR4 to the pool.
The CXL card sits in a dedicated slot at the rear of the chassis, with a high-volume fan providing targeted airflow.
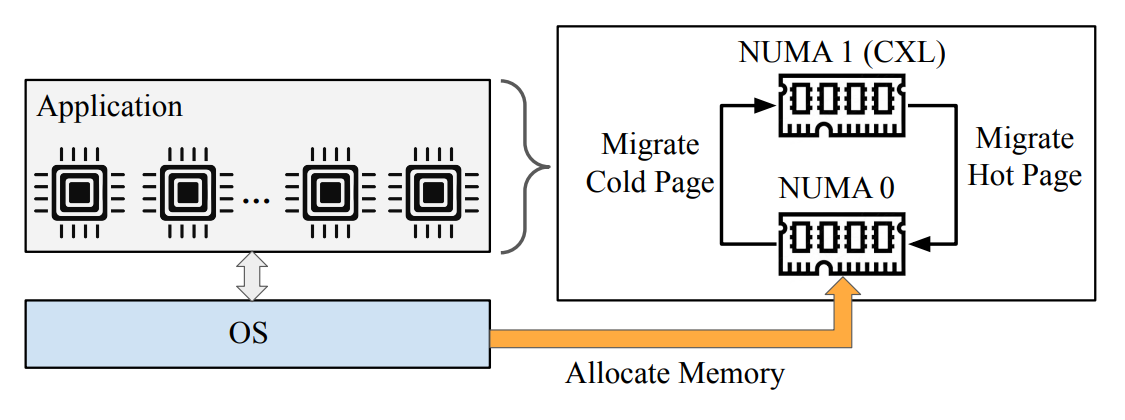
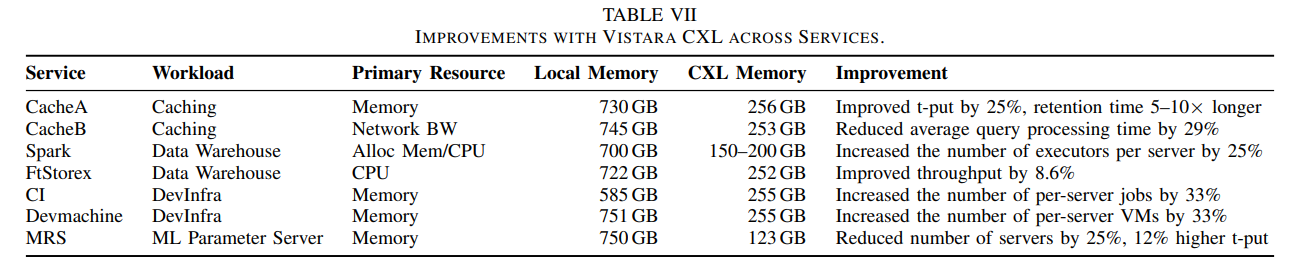
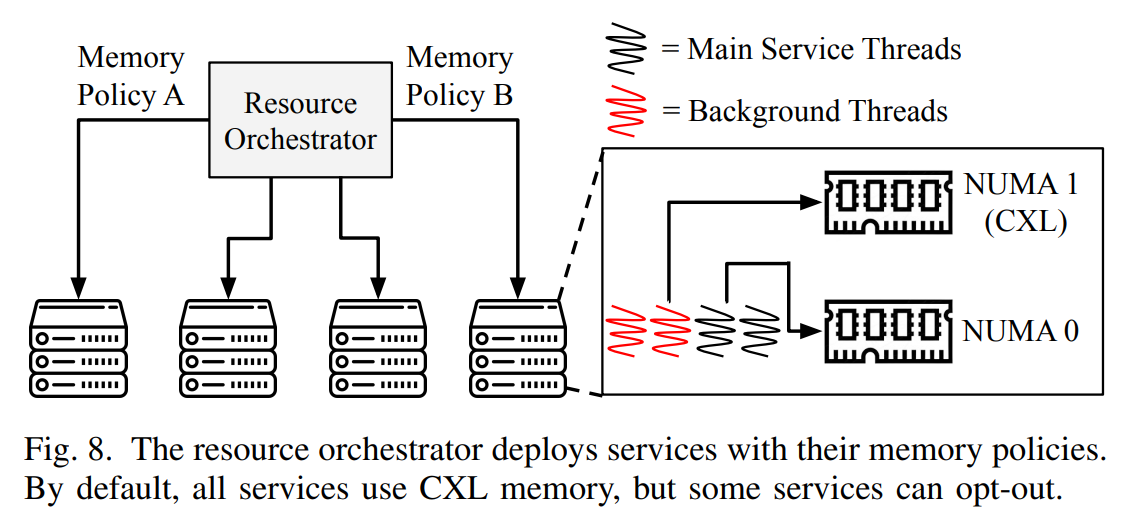
On the software side, Meta built its memory management around Transparent Page Placement (TPP), which lets the OS decide which workloads should use local DDR5 versus the expanded DDR4 pool. The ratio shifts depending on the task — memory-sensitive workloads get more DDR5, while bulk data processing can tap the recycled pool.
The results are significant for hyperscale operators. Meta reports that Vistara reduces the number of servers needed for disaggregated machine learning inference by up to 25%. For distributed caching, average latency dropped by 29%.
Beyond AI inference and caching, Meta is using Vistara for big data processing, databases, and CI/CD build systems — the kinds of workloads that benefit from large memory pools but don’t need the absolute fastest memory access for every byte.
The approach is a practical counterpoint to the industry’s usual playbook of buying new, faster hardware. By keeping DDR4 modules in service for almost twice as long as the servers that originally housed them, Meta is effectively stretching its hardware budget and reducing e-waste at the same time. That math works especially well at the scale of millions of servers.