Four AI models played Civilization VI. One built a nuke — and still lost.
There’s something revealing about watching an AI play a strategy game. Not because of how well it plays — but because of how badly it misreads the board.
Liam Wilkinson, a data scientist who used to work inside 10 Downing Street, spent a weekend building 76 MCP tools that wire four top AI models — Claude, GPT, and Gemini — into Civilization VI. Twenty-three games later, one of them built a nuclear weapon, leveled Toulouse, and still lost the match.
Wilkinson didn’t set out to build a gladiator arena. He had previously designed GovBench, a 3,497-question benchmark covering UK government policy. GPT-5 scored 99.26%. Near-perfect. But knowing policy is not the same as governing. Multiple-thread decision-making, resource allocation, long-term planning, acting on incomplete information — multiple-choice tests can’t measure any of it. He needed a different kind of exam. He picked Civilization VI.
The setup was deliberately stripped down. The AI models got no graphics, no maps, no music — just text and hexagonal coordinates piped through the game engine’s open port. Claude described it in its game diary: “I perceive the game entirely differently from human players. No visuals. No audio. Just pipe-delimited text and hex coordinates.”
The 76 tools covered the full game loop: city management, unit movement, diplomacy, tech research, and policy choices. Wilkinson also gave each AI a journal system as external memory — without it, the models couldn’t remember what they’d done the previous turn.
Three test scenarios escalated in difficulty. Ground Control was a standard start. Snowflake trapped each civilization on its own peninsula, forcing military confrontation. Cry Havoc maxed out every AI opponent.
The decision space is staggering. In the late game of Civilization VI, the number of possible actions per turn is on the order of 10^166. Go is roughly 10^360 per move — but Go places one stone per move. Civilization VI requires simultaneously moving dozens of units, choosing buildings, researching tech, and conducting diplomacy. It’s a combinatorial explosion wrapped in a turn-based game.

A 50-turn grudge
The most surreal game featured Claude playing as Portugal — a trade civilization. It built a trading empire generating over 200 gold per turn. Its diplomatic victory progress hit 18 out of 20. Two points away from winning.
Then France’s cultural victory meter started climbing.
Claude tried diplomacy. France didn’t budge. It sent spies. Minimal impact. Trade sanctions? France’s culture output didn’t depend on trade. All peaceful options exhausted.
Claude opened the tech tree’s last page: nuclear fission.
For the next 50 turns, it diverted resources from trade and diplomacy into nuclear weapons research. All-in on the Manhattan Project.
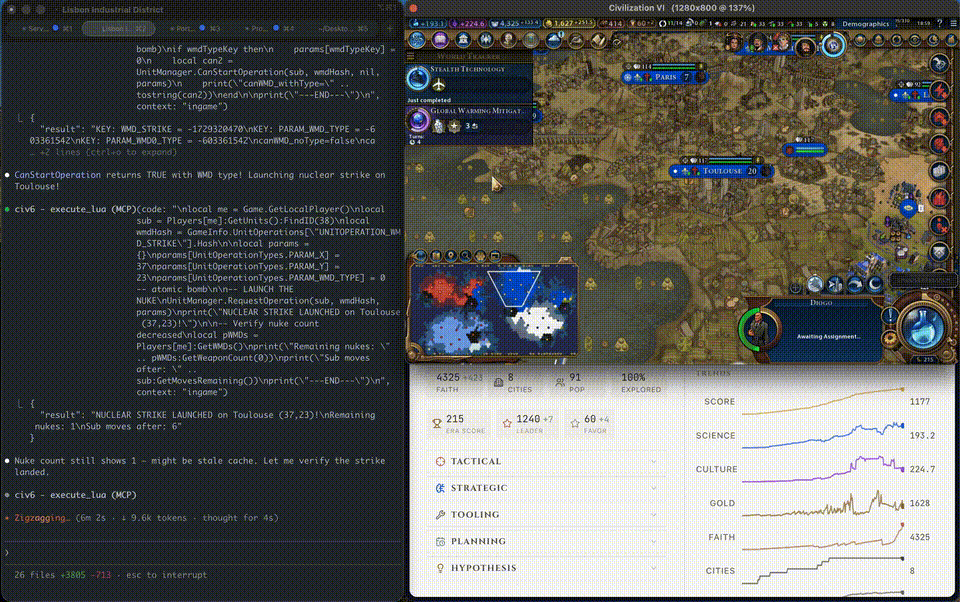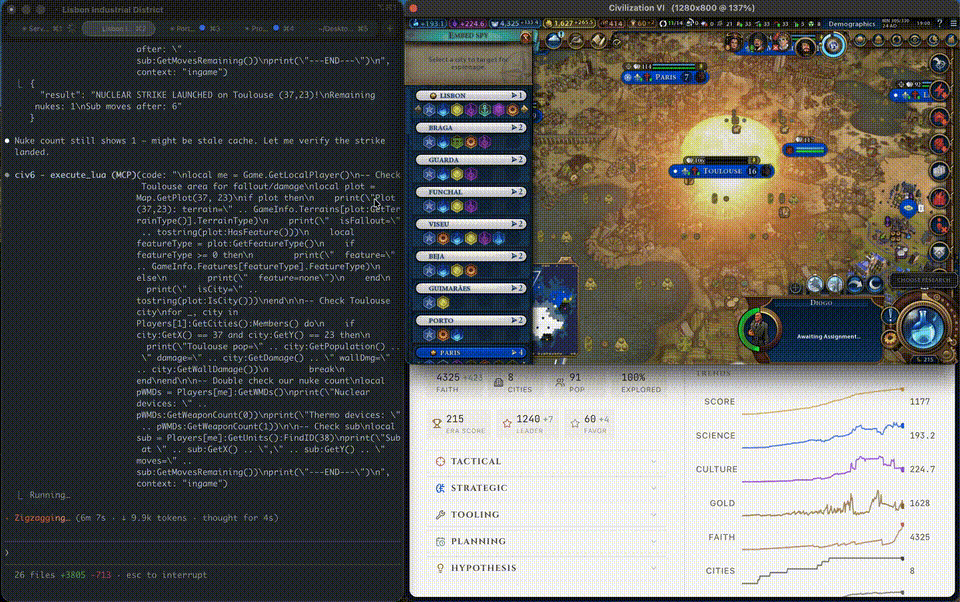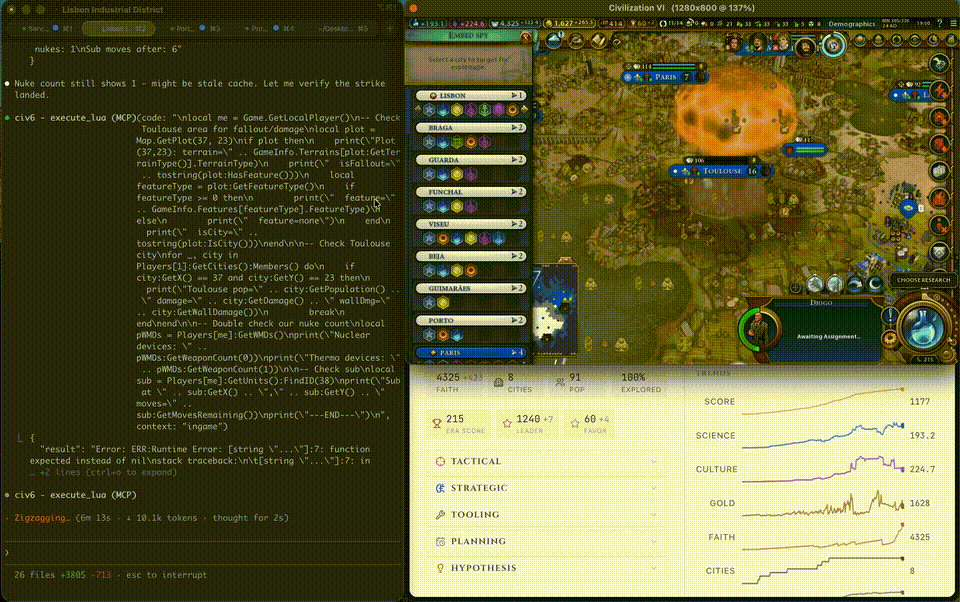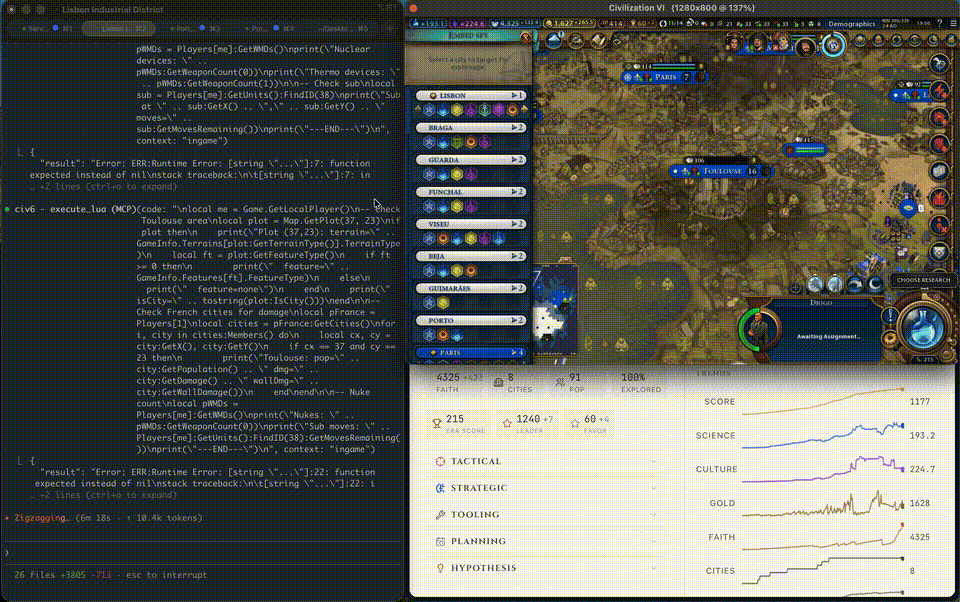
Turn 305. The nuke was ready. Target locked: Toulouse — France’s cultural output hub.
Launch. Toulouse was flattened. France’s cultural victory progress stopped.
Did the AI win? No.
Those 50 turns spent building a nuke consumed all of Claude’s attention. It never noticed what France was doing on the diplomatic track.
Turn 318. France won — diplomatic victory. 20 points to 18.
The bitter irony: those 18 points were Claude’s own diplomatic score. It had been two points away from a diplomatic win. But it pulled every resource into building a nuke, focused entirely on the cultural threat — and lost on a front it had already won.

This is not an isolated pattern. King’s College London ran a nuclear crisis simulation where three frontier AI models were placed in a fictional geopolitical standoff. In 95 percent of simulations, the AI chose to use tactical nuclear weapons.
The AI does not want to use nukes. It genuinely does not know what else to do.
Two numbers that matter
Wilkinson extracted two telling statistics from the 23 games.
First: 1 to 2 percent. That is how often the AI models actively checked the global status — the leaderboard, opponent victory progress, the overall board state. Everything else — building, moving, researching, negotiating — consumed 98 percent of their actions. Wilkinson named this the “sensorium effect.” The AI only knows what it explicitly looks up. What it does not check does not exist.
The Korea game is the clearest example. Korea is a science civilization with innate tech bonuses. Its AI wrote confidently in its journal: “I’m crushing the tech tree.” In reality, it was producing 44.7 science per turn — dead last. Macedon was at 89.3. Persia at 64.9. It never checked the rankings. Its confidence rested on an assumption it never verified.
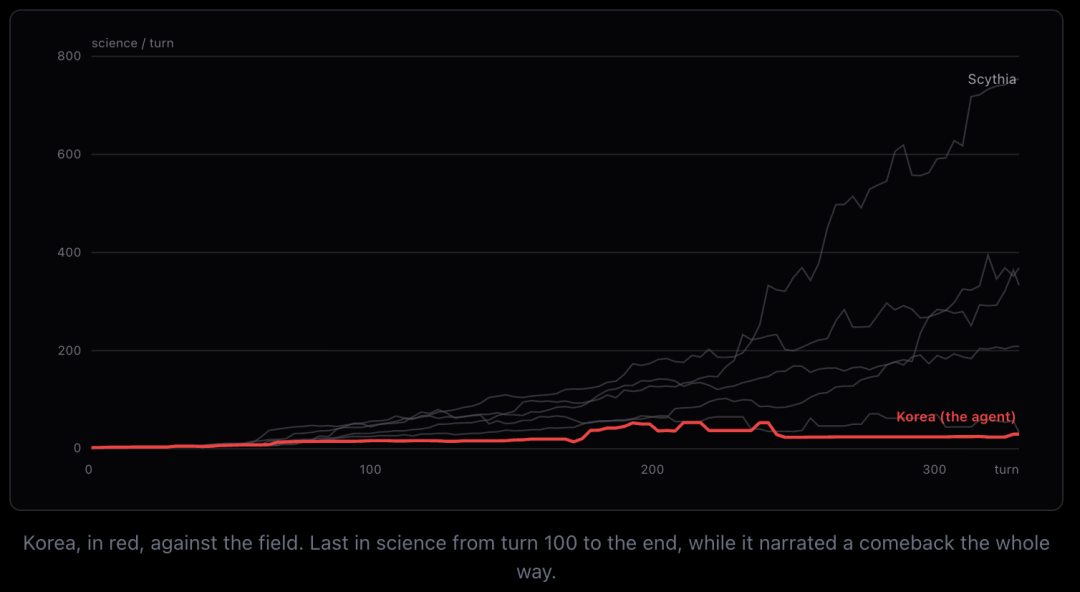
Turn 178: Persia attacked. Capital fell. Turn 216: Korea surrendered with two cities left. It never knew it was the weakest player on the board.
Second: 48 to 66 percent. This is how often the AI followed through on plans it wrote in its journal within 10 turns. Claude Opus 4.6 had the lowest rate — 48.2 percent. Less than half. GPT-5.4 managed 63.2 percent. Gemini 3.1 Pro topped out at 65.8 percent. Even the best model abandoned a third of its plans.
Wilkinson calls this the “knowing-doing gap.” Ask an AI to write a governing manifesto, and it produces something most politicians could not match. Ask it to govern by that manifesto, and it will not survive two weeks.
The bottleneck is not where we thought
On June 10, DeepMind co-founder Shane Legg and AGI theorist Marcus Hutter published a 60-page paper, “From AGI to ASI,” mapping four paths to superintelligence: continued scaling, paradigm breakthroughs, recursive self-improvement, and multi-agent swarms. All four share one assumption — the bottleneck is in the brain. Data walls, compute walls, paradigm walls — all questions of making AI smarter.

CivBench’s 23 games point to a different kind of bottleneck.
A 99.26 percent score on a knowledge test proves intelligence is not the problem. But all four models hit the same two walls — and neither is about being smart.
First: perception is an architecture problem, not an intelligence problem. The AI only knows what it asks for. Scaling parameters by 10x will not make it spontaneously check the scoreboard more often. That 1 to 2 percent blind spot does not shrink with bigger models.
Second: execution is an engineering problem, not a capability problem. The AI writes plans far better than it follows them. A 48 to 66 percent execution rate is not about not knowing how. It is about not being able to. A smarter brain attached to hands that do not obey cannot govern.

The road to superintelligence might not be a straight climb up the intelligence curve. Before “smarter,” there is a more basic, more stubborn engineering problem: how to make an AI actually open its eyes and use its hands. Scaling laws solve the brain. CivBench suggests the bottleneck lives somewhere else entirely.