Li Auto's homegrown AI chip lands at ISCA 2026 — a first for any Chinese car company
When Li Auto took the stage at ISCA 2026 this week, it wasn’t just presenting a paper. It was proving a bet that started four years ago — that an automaker could design a world-class AI chip from scratch, tape it out on a 5nm process, and already have it running in production vehicles.

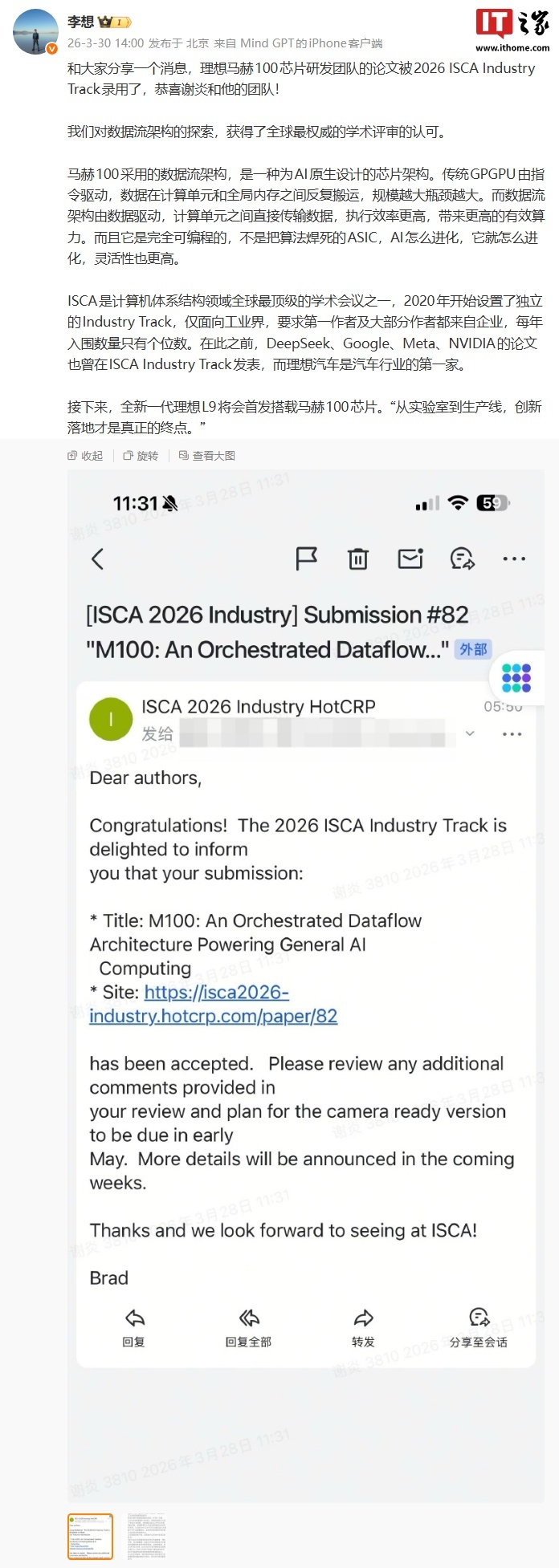
The Mach M100 processor earned a spot at ISCA (International Symposium on Computer Architecture), one of the four top-tier conferences in the field alongside MICRO, HPCA, and ASPLOS. Since the conference established its Industry Track in 2020, Li Auto is the first Chinese automotive company to have a paper accepted. Researchers from Google and Meta also presented at the same event.

The chip is built around a dataflow architecture, which differs fundamentally from the GPGPUs that power most AI inference today. Instead of instruction-driven execution that constantly shuttles data between compute units and global memory, a dataflow model lets data move directly between compute units. Li Auto claims this yields 82% utilization on the chip’s 1280 TOPS of compute capacity.
Manufactured on a 5nm automotive-grade process, the Mach M100 pairs with 8 channels of LPDDR5X memory for 273GB/s of peak bandwidth. A 24-core ARM Cortex-A78AE cluster handles CPU workloads. The architecture follows five design principles: dataflow execution, a cacheless memory hierarchy, tensor-granularity ISA, balanced hardware-software complexity, and a hierarchical tile interconnect. Fully redundant hardware — two SoCs, two MCUs, and two power supply rails — qualifies the chip for ASIL-D, the highest automotive safety integrity level.

Li Auto’s journey to silicon started in 2021 with feasibility studies. The chip project formally launched the following year with a clear mandate: no tweaking existing designs, no cloning. A team of 200 people worked across architecture design, compiler development, thermal systems, and functional safety — all in-house.
Li Auto CEO Li Xiang has described the dataflow approach as natively designed for AI. In a traditional GPGPU, he argued, the instruction-driven model creates bottlenecks as scale grows because data must constantly move between compute units and global memory. The dataflow architecture eliminates that overhead. And unlike an ASIC that hardcodes specific algorithms, the Mach M100 is fully programmable — the architecture can evolve alongside AI models.
The Mach M100 is already shipping in production in the new Li L9 and Li L8 models. From chip architecture design to vehicle delivery, the entire chain was completed in-house.